Greasy Fork is available in English.
picture_collector
Collect pictures of paginated structure picture website
分页图片采集器
介绍
一个图片采集器,用来采集分页结构图片网站的图片。
使用说明
- 安装脚本
- 寻找带有分页结构的图片网站
- 阅读下方文本,编写配置数据
- 在带有分页结构的图片网站使用
概念与约定
在采用分页结构的网站中,称分页所在网页为1级页面,点击分页列表中的一个元素打开的页面为2级页面,一般情况下目标图片的url往往就在2级页面里。如果2级页面里的图片还不是最清晰的,还需要点击目标元素并打开3级页面,那么目标图片的url就在3级页面里,以此类推。通过配置好各级页面选择器,采集器程序将能够遍历访问每一个分页的每一个目标超链接,并进入每一个目标超链接对应的网页,获取目标图片的url,将图片实时展示到前台的采集结果栏中。采集器工作的关键在于表单的数据配置。
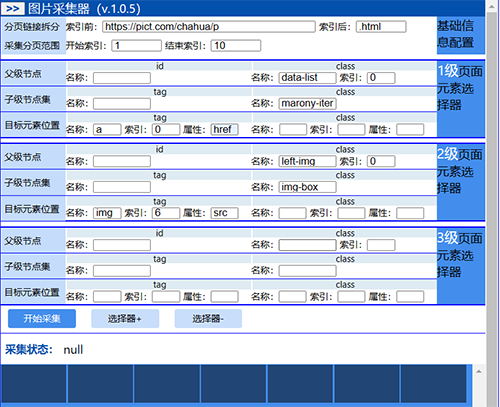
1.采集器基础信息配置
https://pict.com/chahua/p1.html
那么对应基础信息配置应为: 索引前:https://pict.com/chahua/p 索引后:.html 开始索引:1 结束索引:3
2.采集器n级页面选择器配置
为了获取1级页面中每个目标结点元素的超链接,需要借助网页元素的树形结构。由根节点(父结点)找到子结点,由子结点找到与之对应的目标结点。对应于网页中,父结点可以是本页所有目标结点元素的一个共同的box容器,该容器是唯一的,可以通过html元素的“id名”或“类名[n]”来唯一表示。如果1级页面中该容器的类名为“data-list”(class="data-list"),且在页面中是第一个以data-list为类名的元素。那么对应的1级页面选择器的父级结点配置应为:
class ——> 名称:data-list 索引:0
父结点下有若干子节点,每个子结点都是目标结点元素的一个box容器,该容器相对于目标结点是唯一的。如果页面的结构如下:
<div class="data-list">
<div class="marony-item">
<a class="target-link" href="https://pict.com/chahua/23123"></a>
</div>
<div class="marony-item">
<a class="target-link" href="https://pict.com/chahua/34645"></a>
</div>
<div class="marony-item">
<a class="target-link" href="https://pict.com/chahua/45553"></a>
</div>
<div class="marony-item">
<a class="target-link" href="https://pict.com/chahua/89422"></a>
</div>
......
</div>
那么对应的1级页面选择器的子结点集配置应为:
class ——> 名称:marony-item
对应的1级页面选择器的目标元素位置配置应为:
class ——> 名称:target-link 索引:0 属性:href
或者:
tag ——> 名称:a 索引:0 属性:href
其他级的页面配置类似。只是对于2级页面,子结点和目标结点的数量往往等于1而已。对于最后1级页面的目标元素配置,往往是:
tag ——> 名称:img 索引:0 属性:src
程序界面